MoCo & MoCo v2 논문 리뷰
MoCo와 MoCo v2에 대해서 간단하게만 정리해보았습니다.
MoCo
‘Momentum Contrast for Unsupervised Visual Representation Learning’에 대한 정리입니다.
논문링크: https://arxiv.org/abs/1911.05722
Intro
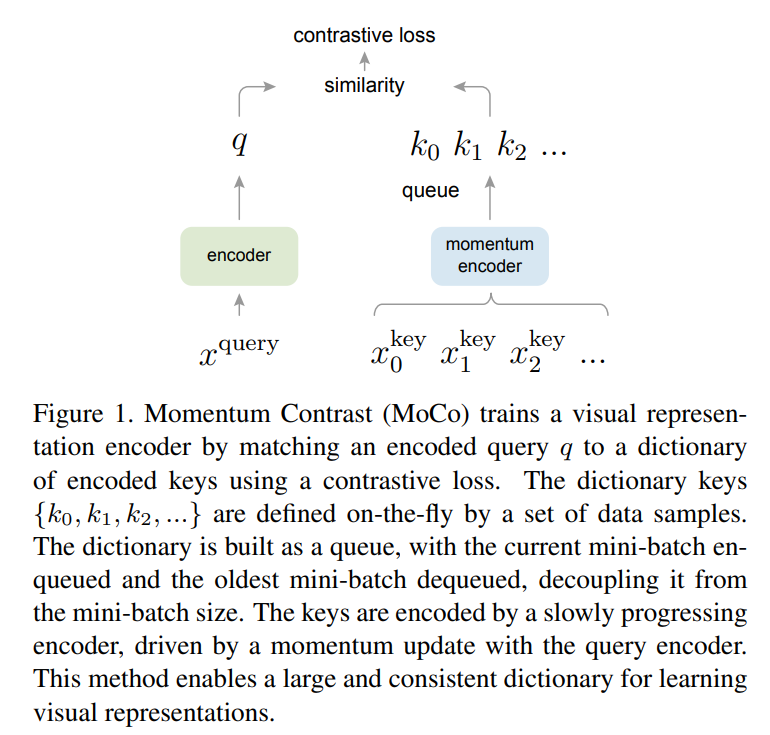
BERT나 GPT 등의 language 모델에서는 tokenized dictionaries를 만들때 단어와 같은 discrete한 signal spaces가 있기에 unsupervised한 모델을 적용하기 어렵습니다. 따라서 contrasive loss를 통한 접근이 대두되고 있으며 dynamic dictionaries 만드는 것으로 해결해보려는 것이 하나의 방법입니다. 이 방법을 위해서는 Key가 데이터로부터 샘플링되고 encoder를 통해서 표현됩니다. 그리고 Encoded된 query가 특정 key와 맞아야하고 나머지와는 유사하지 않도록 학습을 진행합니다. 다시 말해서 encoder를 통과한 q가 있을때 encoder를 통과한 key와의 similar 여부를 contrastive loss로 측정하여 similar한 것들을 찾아내는 것이 목표라고 할 수 있겠습니다.
2가지의 목표
1) large dictionary 2) consistent한 dictionary 이 두 가지 조건을 충족시킬 수 있는 모델을 만드는 것
Why?
1) 큰 dictionary가 연속적이고 고차원적인 visual space를 잘 표현할 수 있음 2) consistent해야 유사성을 비교할 때 그 비교한 것들 역시 consistent함을 유지할 수 있기 때문
How?
1) Queue를 사용하는 dictionary
2) Slowly progressing key encoder
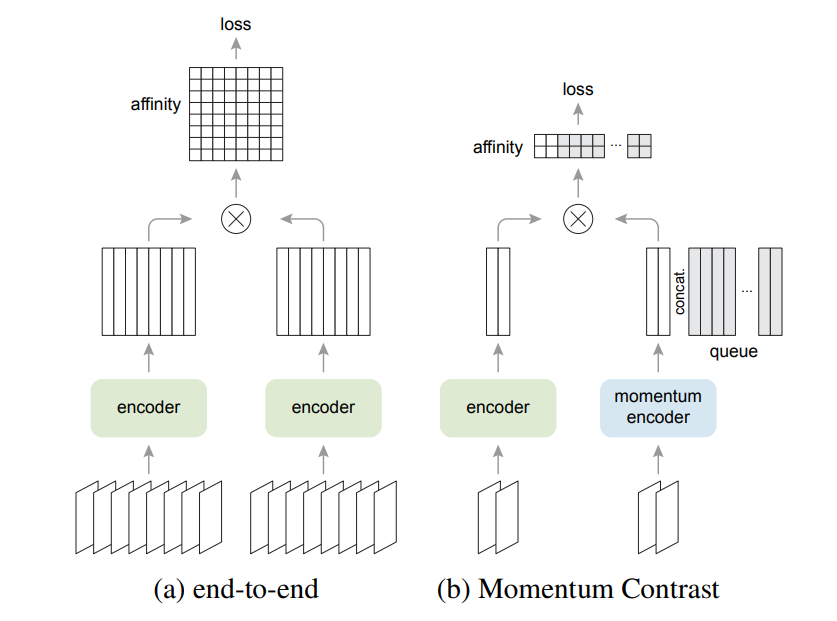
Method
-
InfoNCE
\[\mathcal{L}_q=-log \frac{exp(q \cdot k_+/\tau)}{\sum^K_{i=0} exp(q \cdot k_i/\tau)}\]softmax와 유사, similarity를 통해 positive한 것을 찾고 negative sample들에 대해서는 다르다는 것을 판단하도록
-
query sample $x^q$가 있을 때 $q=f_q(x^q)$, key 역시 마찬가지로 $k=f_k(x^k)$
-
여기서 $f_q$와 $f_k$를 어떻게 사용하느냐가 중요
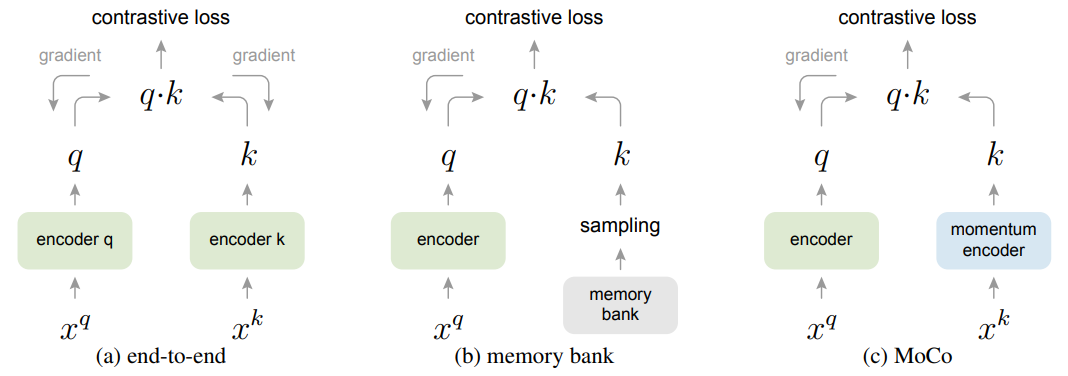
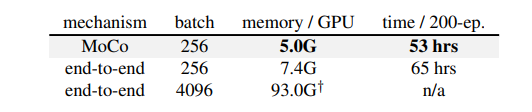
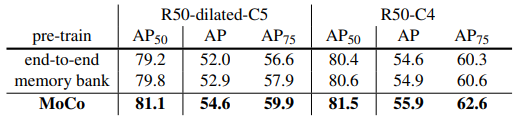
첫번째의 end-to-end 방식의 경우 back propagation을 통해서 update를 진행합니다. 이때 current mini-batch를 dictionary로 활용해서 keys가 consistent하게 encode될 수 있도록 합니다. 하지만 dictionary의 크기가 mini-batch size에 대해서 배가 될 수 있어 GPU 메모리에 의한 제한이 생긴다는 단점이 있습니다. 따라서 큰 배치의 활용이 어렵습니다. 두번째의 memory bank 방식의 경우 데이터셋에 대한 representations를 담고 있는 memory bank를 활용하는 방법으로 end-to-end와는 다르게 dictionary for each mini-batch가 momory bank에서 랜덤하게 뽑혀 사용되는 동시에 back-propagation 역시 진행되지 않습니다. 하지만 consistent함이 떨어지고 메모리 효율성도 MoCo에 비해서 떨어진다고 저자는 말하고 있습니다.
MoCo는 앞서 언급한 것처럼
- dictionary as a queue of data samples
- $f_q$로부터 $f_k$를 카피하는 단순한 방법이 아닌 momentum update를 활용 (급격한 변화를 방지) -> $\theta_k \leftarrow m \theta_k + (1-m)\theta_q$

전반적인 알고리즘을 살펴보면 위와 같습니다.
Experiments & Results
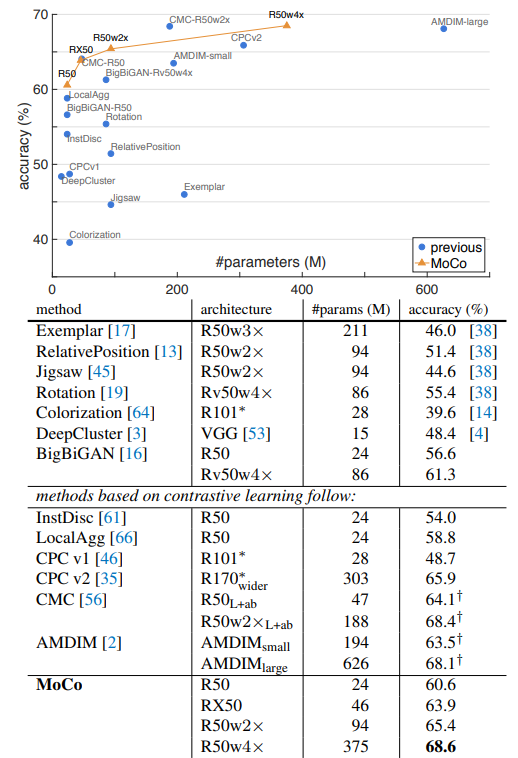
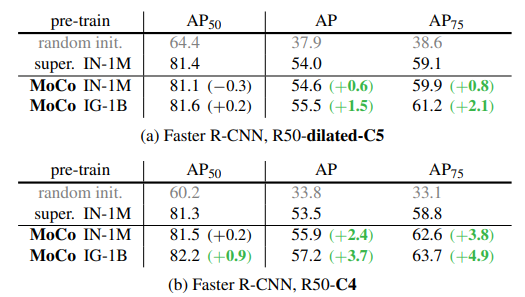

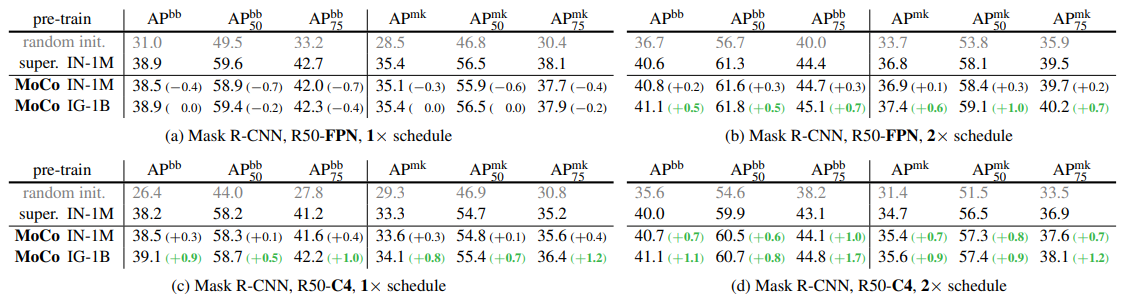
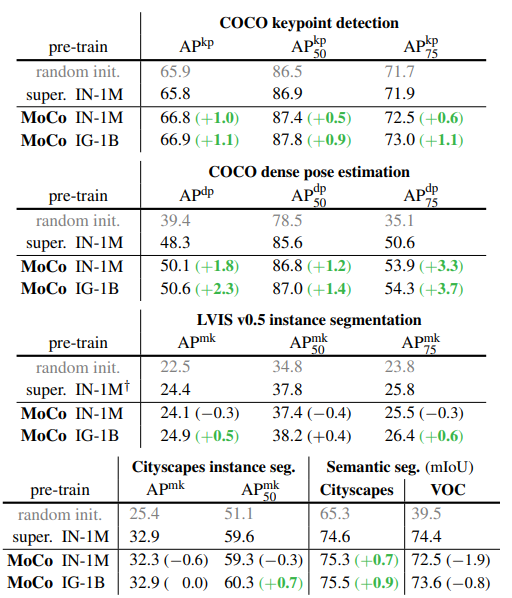
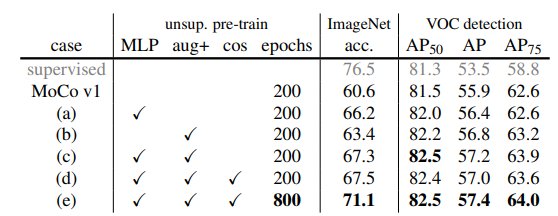
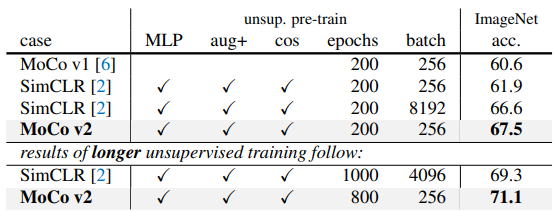
MoCo v2
Method
SimCLR에서 사용되었던 MLP projection head의 사용과 strong data augmentation에 대한 활용을 MoCo에도 적용해보자는 취지 따라서 본 논문에서는 기존의 MoCo에 fc projection head MLP head, stronger data augmentation, cosine learning rate schedule을 ablation study로 진행해보았고 결과는 아래와 같습니다.